Edit detail for RegularniVyrazy revision 1 of 1
| 1 | ||
|
Editor: pycz
Time: 2007/09/04 16:43:58 GMT+0 |
||
| Note: | ||
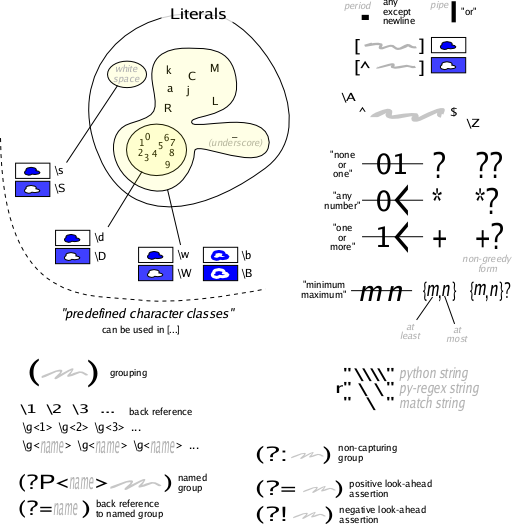
changed: - Regulární výrazy v Pythonu ============================ Jako základ (pokud není uvedeno jinak) je ve všech následujících příkladech brán tento idiom: >>> python=u"""Python je skvělý objektově orientovaný, interpretovaný a interaktivní programovací jazyk. Často je srovnáván (samozřejmě příznivě, zeptejte se Googla ;-)) s jazyky C, Visual Basic, Java, Perl, Scheme,.... a je s ním daleko větší zábava.""" ;-) Neregulární výrazy ------------------ Člověk dlouho vystačí při hledání či nahrazování řetězců v textu s obyčejnými funkcemi, jako např.:: >>> print python.find(u"skvělý") 10 >>> print python.replace(u"skvělý",u"výborný") Python je výborný objektově orientovaný, interpretovaný a interaktivní programov ací jazyk. Často je srovnáván (samozřejmě příznivě, zeptejte se Googla ;-)) s ja zyky C, Visual Basic, Java, Perl, Scheme,.... a je s ním daleko větší zábava. >>> print python.count(u"a") 19 Jednoho dne však potřebuje, najít a vypsat např. všechna slova, která začínají na velká písmena, všechny emailové adresy nebo nahradit všechny odkazy za html formou tagu <a>. A v té chvíli buď začne vytvářet šíleně složité algoritmy za použití výše uvedených funkcí nebo se naučí používat regulární výrazy. Jednoduché příklady, ------------------- které se sice dají dělat dělat i pomocí výše uvedených metod, ale zde slouží k seznámení s modulem re.:: >>> import re >>> re.search(u"skvělý", python) <_sre.SRE_Match object at 0x00A37138> >>> dir(re.search(u"skvělý", python)) ['__copy__', '__deepcopy__', 'end', 'expand', 'group', 'groupdict', 'groups', 's pan', 'start'] >>> re.search(u"skvělý", python).start() 10 >>> print re.sub(u"skvělý",u"výborný", python) Python je výborný objektově orientovaný, interpretovaný a interaktivní programov ací jazyk. Často je srovnáván (samozřejmě příznivě, zeptejte se Googla ;-)) s ja zyky C, Visual Basic, Java, Perl, Scheme,.... a je s ním daleko větší zábava. >>> re.findall(u"a", python) [u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u 'a', u'a', u'a', u'a', u'a', u'a'] >>> len(re.findall(u"a", python)) 19 Zatím regulární výrazy jsou složitější než neregulární. Jejich krása však teprve přichází. Základní sémantika ------------------ Základ re výrazů je jiný, než je zvyklá většina z Windows/Linuxu. Ve Windows se tato konvence používá výhradně na hledání souborů, v re však na prohledávání jakéhokoliv textu. Chceme-li obyčejně vyhledat všechny soubory, píšeme `*`. V re to je však `.*`. Tečka znamená jakýkoliv jeden znak, `*` pak, že se může libovolněkrát opakovat. ? obyčejně znamená přesně jeden znak, v re to je . (tečka). Těchto tzv. *metaznaků* je mnohem více a umí mnohem více, než jakýkoliv začátečník může jen doufat nebo si vůbec představit. Regulární příklady se dají použít na následující typy úloh. **Poznámka pro váhavé**: neváhejte sem přidávat další příklady, třeba vždy, když se vám podaří něco nového s regulárními vzory vyřešit: Najdi všechna slova, která začínají na "o" ........................................... >>> re.findall("\Wo\w*", python, re.U) [u' objektov\\u011b', u' orientovan\\xfd'] "\\Wo\\w*": - `\\W` značí v hatmatilce regulárních výrazů jakýkoliv jeden znak, který je jiný než písmeno. Tedy mezera, tečka, uvozovky, Enter, apod. Před naším slovem nemusí být totiž jen mezera. - "o" - zde je znak "sám za sebe". Tedy po nějakém znaku musí být "o". - Dál může pokračovat jakékoliv písmeno (`\\w` - jakékoliv písmeno kromě mezery - tedy opak `\\W`), které se může libovolněkrát (0x, 1x, 2x, ....) opakovat (`*`) - pokaždé to může být písmeno jiné. python: prohledávaný řetězec re.U: aby nám to fungovalo i pěkně na češtinu, na Unicode ![u' objektov\\u011b', u' orientovan\\xfd']: připadá-li vám, že to není česky, tak se mýlíte. Jen Python neumí v seznamu česky nativně tisknout, což se dá obejít tím, že seznam budete procházet v cyklu a tisknout jednotlivé položky zvlášť. Najdi všechna slova, která začínají na malé nebo i velké S ........................................................... >>> re.findall(" [sS]\w*", python, re.U) [u' skv\u011bl\xfd', u' srovn\xe1v\xe1n', u' se', u' s', u' Scheme', u' s'] Téměř to samé jako minule, jen: ![sS]: Na začátku může být buď ([]) s nebo S. Buď jedno nebo druhé. Najdi text, obsah a priponu .............................. :: # -*- coding: cp1250 -*- import re text="""---bladsasda text: ahoj obsah: jirka.novy pripona: txt blasdadsbla --- ---blaasdasdla bla text: nazdar obsah: marek.zeleny pripona: txt blaasdasdbla --- ---blasdasd bla bla text: cau obsah: tonda.vokoun pripona: txt bla asdasda ---""" # "text:" - hledá slovo "text:" # "*" - předchozí znak se může libovolněkrát opakovat # " *" - mezera se může libovolněkrát oprakovat # \w - jedno písmeno, jakékoliv # \w+ - písmeno se může libovolněkrát opakovat, nejméně však jednou - jinými slovy je to "slovo" # (\w+) - bude zahrnuto do výsledku hledání jako např. skupina 1 = vyskyt.group(1) # "obsah: *" - dále musí následovat slovo "obsah" následovaný libovolným počtem mezer # (\w+\.\w+) - dvě slova oddělená tečkou, ve výsledcích to bude skupina 2 # atd. atd. vzor="text: *(\w+) *obsah: *(\w+\.\w+) *pripona: *(\w+)" # finditer postupně nalézá všechny výskyty v textu - v tomto případě po řádcích for vyskyt in re.finditer(vzor, text): # vytiskne skupinu 1 (to co je ve vzoru v první závorce, skuponu i tři) print vyskyt.group(1)+" - "+ vyskyt.group(2)+" - "+ vyskyt.group(3) Najdi všechny emailové adresy ............................. waiting for you ;-) Více aneb Záložky, Oblíbené ------------------------------ - http://docs.python.org/lib/module-re.html - http://www.google.cz/search?q=regul%C3%A1rn%C3%AD+v%C3%BDrazy&start=0&ie=utf-8&oe=utf-8 - http://www.google.cz/search?hs=rhc&hl=cs&q=python+re&btnG=Hledat&lr= Grafické znázornění -------------------- .. image:: http://wiki.python.org/moin/RegularExpression?action=AttachFile&do=get&target=regex_characters.png .. image:: http://taoriver.net/img/for_pi/regex_flags.png
Regulární výrazy v Pythonu
Jako základ (pokud není uvedeno jinak) je ve všech následujících příkladech brán tento idiom:
>>> python=u"""Python je skvělý objektově orientovaný, interpretovaný a interaktivní programovací jazyk. Často je srovnáván (samozřejmě příznivě, zeptejte se Googla ;-)) s jazyky C, Visual Basic, Java, Perl, Scheme,.... a je s ním daleko větší zábava."""
;-)
Neregulární výrazy
Člověk dlouho vystačí při hledání či nahrazování řetězců v textu s obyčejnými funkcemi, jako např.:
>>> print python.find(u"skvělý") 10 >>> print python.replace(u"skvělý",u"výborný") Python je výborný objektově orientovaný, interpretovaný a interaktivní programov ací jazyk. Často je srovnáván (samozřejmě příznivě, zeptejte se Googla ;-)) s ja zyky C, Visual Basic, Java, Perl, Scheme,.... a je s ním daleko větší zábava. >>> print python.count(u"a") 19
Jednoho dne však potřebuje, najít a vypsat např. všechna slova, která začínají na velká písmena, všechny emailové adresy nebo nahradit všechny odkazy za html formou tagu <a>. A v té chvíli buď začne vytvářet šíleně složité algoritmy za použití výše uvedených funkcí nebo se naučí používat regulární výrazy.
Jednoduché příklady,
které se sice dají dělat dělat i pomocí výše uvedených metod, ale zde slouží k seznámení s modulem re.:
>>> import re >>> re.search(u"skvělý", python) <_sre.SRE_Match object at 0x00A37138> >>> dir(re.search(u"skvělý", python)) ['__copy__', '__deepcopy__', 'end', 'expand', 'group', 'groupdict', 'groups', 's pan', 'start'] >>> re.search(u"skvělý", python).start() 10 >>> print re.sub(u"skvělý",u"výborný", python) Python je výborný objektově orientovaný, interpretovaný a interaktivní programov ací jazyk. Často je srovnáván (samozřejmě příznivě, zeptejte se Googla ;-)) s ja zyky C, Visual Basic, Java, Perl, Scheme,.... a je s ním daleko větší zábava. >>> re.findall(u"a", python) [u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u'a', u 'a', u'a', u'a', u'a', u'a', u'a'] >>> len(re.findall(u"a", python)) 19
Zatím regulární výrazy jsou složitější než neregulární. Jejich krása však teprve přichází.
Základní sémantika
Základ re výrazů je jiný, než je zvyklá většina z Windows/Linuxu. Ve Windows se tato konvence používá výhradně na hledání souborů, v re však na prohledávání jakéhokoliv textu.
Chceme-li obyčejně vyhledat všechny soubory, píšeme *. V re to je však .*. Tečka znamená jakýkoliv jeden znak, * pak, že se může libovolněkrát opakovat. ? obyčejně znamená přesně jeden znak, v re to je . (tečka). Těchto tzv. metaznaků je mnohem více a umí mnohem více, než jakýkoliv začátečník může jen doufat nebo si vůbec představit.
Regulární příklady se dají použít na následující typy úloh. Poznámka pro váhavé: neváhejte sem přidávat další příklady, třeba vždy, když se vám podaří něco nového s regulárními vzory vyřešit:
Najdi všechna slova, která začínají na "o"
>>> re.findall("\Wo\w*", python, re.U)
[u' objektov\\u011b', u' orientovan\\xfd']
- "\Wo\w*":
- \W značí v hatmatilce regulárních výrazů jakýkoliv jeden znak, který je jiný než písmeno. Tedy mezera, tečka, uvozovky, Enter, apod. Před naším slovem nemusí být totiž jen mezera.
- "o" - zde je znak "sám za sebe". Tedy po nějakém znaku musí být "o".
- Dál může pokračovat jakékoliv písmeno (\w - jakékoliv písmeno kromě mezery - tedy opak \W), které se může libovolněkrát (0x, 1x, 2x, ....) opakovat (*) - pokaždé to může být písmeno jiné.
- python:
- prohledávaný řetězec
- re.U:
- aby nám to fungovalo i pěkně na češtinu, na Unicode
- [u' objektov\u011b', u' orientovan\xfd']:
- připadá-li vám, že to není česky, tak se mýlíte. Jen Python neumí v seznamu česky nativně tisknout, což se dá obejít tím, že seznam budete procházet v cyklu a tisknout jednotlivé položky zvlášť.
Najdi všechna slova, která začínají na malé nebo i velké S
>>> re.findall(" [sS]\w*", python, re.U)
[u' skv\u011bl\xfd', u' srovn\xe1v\xe1n', u' se', u' s', u' Scheme', u' s']
Téměř to samé jako minule, jen:
- [sS]:
- Na začátku může být buď ([]) s nebo S. Buď jedno nebo druhé.
Najdi text, obsah a priponu
# -*- coding: cp1250 -*-
import re
text="""---bladsasda text: ahoj obsah: jirka.novy pripona: txt blasdadsbla ---
---blaasdasdla bla text: nazdar obsah: marek.zeleny pripona: txt blaasdasdbla ---
---blasdasd bla bla text: cau obsah: tonda.vokoun pripona: txt bla asdasda ---"""
# "text:" - hledá slovo "text:"
# "*" - předchozí znak se může libovolněkrát opakovat
# " *" - mezera se může libovolněkrát oprakovat
# \w - jedno písmeno, jakékoliv
# \w+ - písmeno se může libovolněkrát opakovat, nejméně však jednou - jinými slovy je to "slovo"
# (\w+) - bude zahrnuto do výsledku hledání jako např. skupina 1 = vyskyt.group(1)
# "obsah: *" - dále musí následovat slovo "obsah" následovaný libovolným počtem mezer
# (\w+\.\w+) - dvě slova oddělená tečkou, ve výsledcích to bude skupina 2
# atd. atd.
vzor="text: *(\w+) *obsah: *(\w+\.\w+) *pripona: *(\w+)"
# finditer postupně nalézá všechny výskyty v textu - v tomto případě po řádcích
for vyskyt in re.finditer(vzor, text):
# vytiskne skupinu 1 (to co je ve vzoru v první závorce, skuponu i tři)
print vyskyt.group(1)+" - "+ vyskyt.group(2)+" - "+ vyskyt.group(3)
Najdi všechny emailové adresy
waiting for you ;-)
Více aneb Záložky, Oblíbené
Grafické znázornění